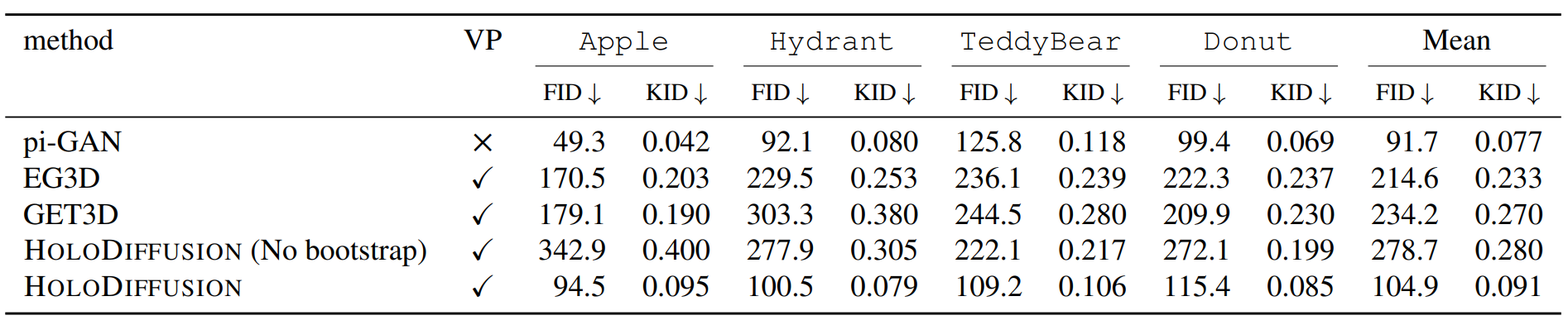
Diffusion models have emerged as the best approach for generative modeling of 2D images. Part of their success is due to the possibility of training them on millions if not billions of images with a stable learning objective. However, extending these models to 3D remains difficult for two reasons. First, finding a large quantity of 3D training data is much harder than for 2D images. Second, while it is conceptually trivial to extend the models to operate on 3D rather than 2D grids, the associated cubic growth in memory and compute complexity makes this unfeasible. We address the first challenge by introducing a new diffusion setup that can be trained, end-to-end, with only posed 2D images for supervision, and the second challenge by proposing an image formation model that decouples model memory from spatial memory. We evaluate our method on real-world data, using the CO3D dataset which has not been used to train 3D generative models before. We show that our diffusion models are scalable, train robustly, and are competitive in terms of sample quality and fidelity to existing approaches for 3D generative modeling.
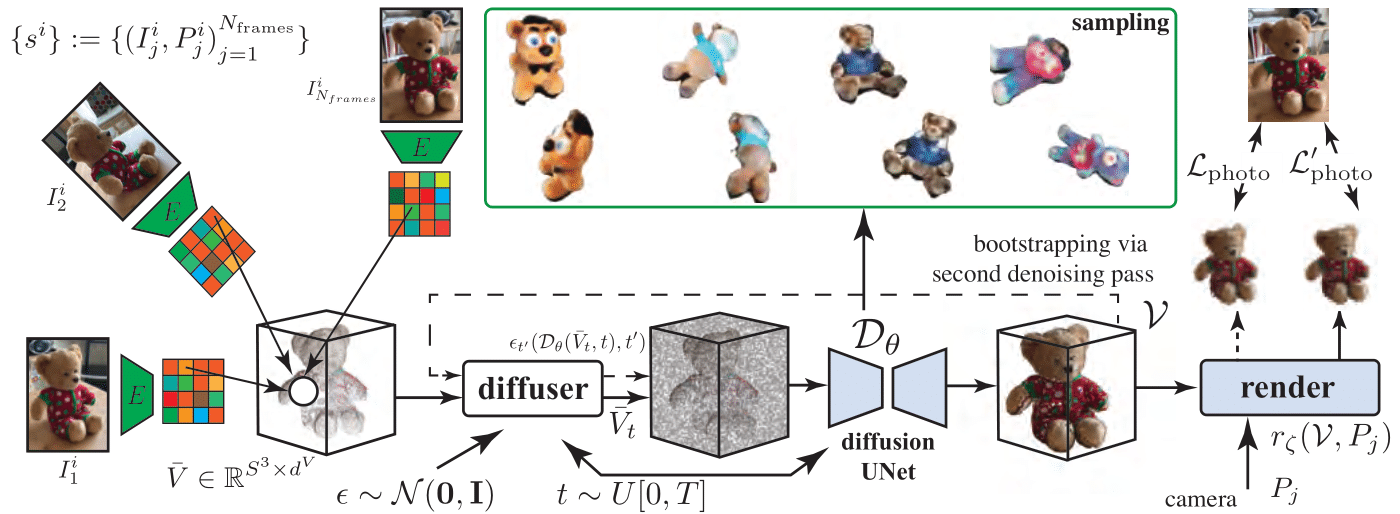
Method Overview. Our HoloDiffusion that takes as input video frames for category-specific videos \( \lbrace s^i \rbrace \) and produces a diffusion-based generative model \( \mathcal{D}_\theta \). The model is trained with only posed image supervision \(\lbrace (I_j^i , P_j^i )\rbrace\), without access to 3D ground-truth. Once trained, the model can generate view-consistent results from novel camera locations. Please refer to Sec. 3 of the paper for details.
Samples with colour and geometry. Samples drawn from the HoloDiffusion model trained on Co3Dv2 are shown with the colour render (left) and the shaded-depth renders (right). The geometries are mostly clean, but include the base plane due to the real-object setting of Co3Dv2.
@inproceedings{karnewar2023holodiffusion,
title={HoloDiffusion: Training a {3D} Diffusion Model using {2D} Images},
author={Karnewar, Animesh and Vedaldi, Andrea and Novotny, David and Mitra, Niloy},
booktitle={Proceedings of the IEEE/CVF conference on computer vision and pattern recognition},
year={2023}
}
Animesh and Niloy were partially funded by the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No. 956585. This research has also been supported by MetaAI and the UCL AI Centre. Finally, Animesh thanks Alexia Jolicoeur-Martineau for the the helpful and insightful guidance on diffusion models.