Diffusion-based image generators can now produce high-quality and diverse samples, but their success has yet to fully translate to 3D generation: existing diffusion methods can either generate low-resolution but 3D consistent outputs, or detailed 2D views of 3D objects but with potential structural defects and lacking view consistency or realism. We present HoloFusion, a method that combines the best of these approaches to produce high-fidelity, plausible, and diverse 3D samples while learning from a collection of multi-view 2D images only. The method first generates coarse 3D samples using a variant of the recently proposed HoloDiffusion generator. Then, it independently renders and upsamples a large number of views of the coarse 3D model, super-resolves them to add detail, and distills those into a single, high-fidelity implicit 3D representation, which also ensures view-consistency of the final renders. The super-resolution network is trained as an integral part of HoloFusion, end-to-end, and the final distillation uses a new sampling scheme to capture the space of super-resolved signals. We compare our method against existing baselines, including DreamFusion, Get3D, EG3D, and HoloDiffusion, and achieve, to the best of our knowledge, the most realistic results on the challenging CO3Dv2 dataset.

Overview. HoloFusion, which trains the 3D denoiser network \(D_\theta\), is augmented with the 2D 'super-resolution' diffusion model \(D_\beta\). Both models are trained end-to-end by supervising their outputs with 2D photometric error. Please refer to the section 3 of the paper for details.

Distillation. HoloFusion distills a single highresolution voxel grid \(V^H_0\) by minimizing a top-k patchremix loss \(\mathcal{L}_\text{distil}\) between the grid renders \(R_{\eta'} (V^H_0, C) \) and a bank \(I_C\) of \(K = 5\) high-res images output by the 2D diffusion upsampler \(D_\beta\) for each scene camera \(C\). Please refer to the section 3.3 of the paper for details.
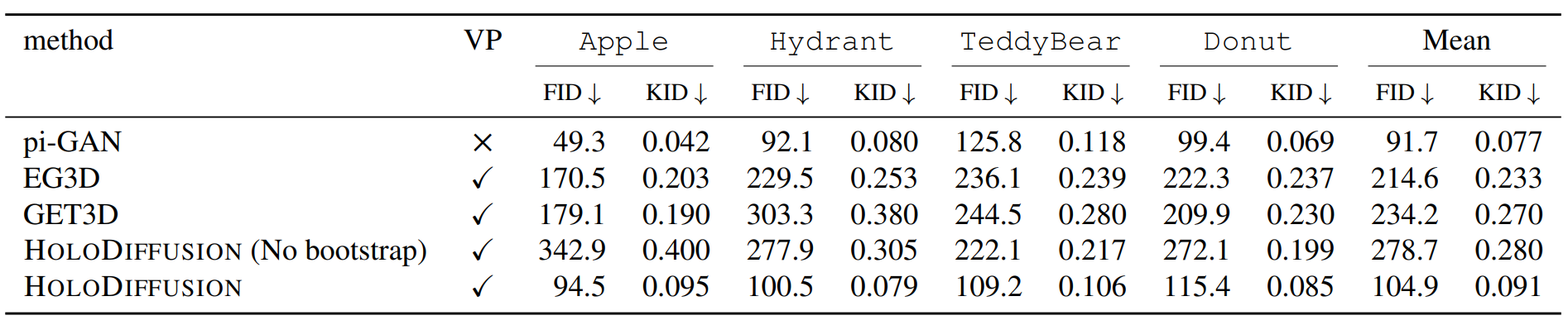
FID \( (\downarrow) \) and KID \( (\uparrow) \) on 4 classes of CO3Dv2. We compare with 3D generative modeling baselines (rows 1 - 5); with an SDS distillation-based Stable-DreamFusion (row 6); and with ablations of our HoloFusion (rows 7-8). The column “VP” denotes whether renders of a method are 3D view-consistent or not.
Comparisons with 3D Generative Baselines. PiGAN generates non-3D-consistent samples, while EG3D and GET3D generates with severe artifacts on the Real-captured Co3Dv2 dataset. Stable-DreamFusion generates 3D-consistent samples but with less details and realism. HoloFusion generates high-quality 3D consistent samples.
Comparisons with HoloDiffusion variants. HoloDiffusion samples are 3D consistent but lack details and realism. HoloDiffusion* baseline shows the output of the 2D superresolution network directly without the 2nd distillation stage.
Ablation experiments. SDS version produces smooth textures and washes out the high-frequency details. MSE version produces floaters and view-point inconsistent artifacts (see the white patches on the hat of the TeddyWizard). Ours on the other hand, produces view-consistent and realistic looking results.
More qualitative samples. Random, uncurated samples generated by our HoloFusion on different classes of the Co3DV2 dataset. Our approach generates high quality 3D view-consistent results across all classes.
@inproceedings{karnewar2023holofusion,
title={HoloFusion: Towards Photo-realistic 3D Generative Modeling},
author={Karnewar, Animesh and Mitra, Niloy J and Vedaldi, Andrea and Novotny, David},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year={2023}
}
Animesh and Niloy were partially funded by the European Union's Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No. 956585. This research has also been supported by MetaAI and the UCL AI Centre. Finally, Animesh is grateful to The Rabin Ezra Scholarship Fund being a recipient of their esteemed fellowship for the year 2023.



